from great_tables import GT, style, loc
import pandas as pd
df_comparacion = pd.DataFrame({
"Métrica": ["AUC (ROC)", "Accuracy", "F1-score", "Recall", "Precision"],
"scikit-learn": [0.6539, 0.6907, 0.4335, 0.5928, 0.3416],
"PySpark": [0.7676, 0.8117, 0.7432, 0.8117, 0.8129]
})
(GT(df_comparacion)
.tab_header(title="Comparación de métricas", subtitle="scikit-learn vs PySpark")
.fmt_number(columns=["scikit-learn", "PySpark"], decimals=4)
.tab_style(
style=style.fill(color="#d4edda"),
locations=loc.body(columns="PySpark")
)
.tab_style(
style=style.text(weight="bold"),
locations=loc.column_labels()
)
)PySpark superó a scikit-learn en todas las métricas evaluadas. El AUC pasó de 0.6539 a 0.7676 y el F1-score de 0.43 a 0.74 siendo esta última la diferencia más notable. Esto se explica principalmente porque scikit-learn usó class_weight=‘balanced’ que sacrifica accuracy general para detectar más defaults mientras que PySpark entrenó sin ese ajuste favoreciendo la clase mayoritaria.
df_tiempos = pd.DataFrame({
"Etapa": ["Entrenamiento (Grid Search)", "Predicción en test"],
"scikit-learn (s)": [1030.47, 5.67],
"PySpark (s)": [565.51, 1.17]
})
(GT(df_tiempos)
.tab_header(title="Tiempos de cómputo", subtitle="scikit-learn vs PySpark")
.fmt_number(columns=["scikit-learn (s)", "PySpark (s)"], decimals=2)
.tab_style(
style=style.fill(color="#d4edda"),
locations=loc.body(columns="PySpark (s)")
)
.tab_style(
style=style.text(weight="bold"),
locations=loc.column_labels()
)
)En cuanto a tiempos PySpark fue significativamente más eficiente completando el grid search en 565 segundos frente a los 1030 de scikit-learn — casi el doble de rápido. La predicción también fue más veloz con 1.17 segundos vs 5.67 de scikit-learn sobre el mismo conjunto de prueba lo que confirma la ventaja de PySpark para procesar grandes volúmenes de datos.
Visualización comparativa¶
import matplotlib.pyplot as plt
import numpy as np
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
metricas = df_comparacion.index.tolist()
x = np.arange(len(metricas))
width = 0.35
bars1 = axes[0].bar(x - width/2, df_comparacion["scikit-learn"], width, label="scikit-learn", color="#4C72B0")
bars2 = axes[0].bar(x + width/2, df_comparacion["PySpark"], width, label="PySpark", color="#DD8452")
axes[0].set_title("Comparación de métricas de evaluación")
axes[0].set_xticks(x)
axes[0].set_xticklabels(metricas, rotation=15)
axes[0].set_ylim(0, 1)
axes[0].legend()
axes[0].set_ylabel("Valor")
for bar in bars1:
axes[0].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f"{bar.get_height():.3f}", ha="center", va="bottom", fontsize=8)
for bar in bars2:
axes[0].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f"{bar.get_height():.3f}", ha="center", va="bottom", fontsize=8)
etapas = df_tiempos.index.tolist()
x2 = np.arange(len(etapas))
bars3 = axes[1].bar(x2 - width/2, df_tiempos["scikit-learn (s)"], width, label="scikit-learn", color="#4C72B0")
bars4 = axes[1].bar(x2 + width/2, df_tiempos["PySpark (s)"], width, label="PySpark", color="#DD8452")
axes[1].set_title("Comparación de tiempos de cómputo (segundos)")
axes[1].set_xticks(x2)
axes[1].set_xticklabels(etapas, rotation=15)
axes[1].legend()
axes[1].set_ylabel("Segundos")
for bar in bars3:
axes[1].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 10,
f"{bar.get_height():.0f}s", ha="center", va="bottom", fontsize=8)
for bar in bars4:
axes[1].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 10,
f"{bar.get_height():.0f}s", ha="center", va="bottom", fontsize=8)
plt.tight_layout()
plt.show()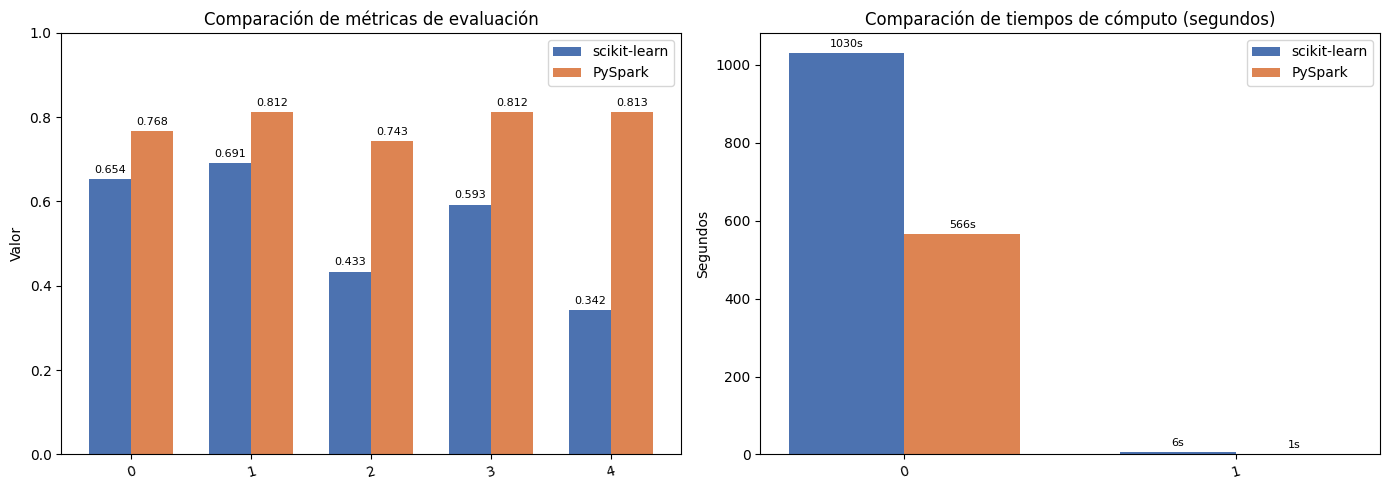
Reflexión crítica¶
¿Qué entorno fue más rápido?
PySpark fue casi el doble de rápido en el grid search (565s vs 1030s) a pesar de que scikit-learn usó paralelismo con n_jobs=-1. Esto se debe a que PySpark distribuye el trabajo a nivel de particiones RDD aprovechando mejor los recursos del sistema. Para predicción PySpark también fue más rápido (1.17s vs 5.67s) sobre 268k filas lo que muestra su ventaja para inferencia a escala.
¿Cuál fue más preciso?
PySpark obtuvo mejores métricas en todas las categorías con AUC de 0.7676 vs 0.6539 de scikit-learn y F1 de 0.74 vs 0.43. Sin embargo esta diferencia puede explicarse parcialmente porque scikit-learn usó class_weight=‘balanced’ para compensar el desbalance de clases lo que afectó sus métricas de accuracy pero mejoró el recall de la clase minoritaria. También hubo diferencias en el preprocesamiento y las variables usadas en cada entorno.
¿Cuándo es útil PySpark?
PySpark es útil cuando el dataset no cabe en la memoria de una sola máquina o cuando se necesita escalar el procesamiento a múltiples nodos. En este proyecto con 1.3M filas ya se notaron las ventajas en velocidad de entrenamiento y predicción. Para datasets más pequeños scikit-learn es más simple de implementar y suficiente.
¿Qué aporta LIME?
LIME permite entender por qué el modelo tomó una decisión específica en un caso individual. En un contexto financiero esto es crítico porque un banco no puede rechazar un préstamo sin poder explicar la razón. LIME convierte el modelo de caja negra en algo interpretable localmente mostrando qué variables empujaron la predicción hacia default o hacia pago en cada caso concreto. En este proyecto variables como bc_util, fico_range_high y mo_sin_old_rev_tl_op fueron las más influyentes en las predicciones individuales.
Conclusión general¶
El preprocesamiento con scikit-learn permitió reducir el dataset de 151 a 70 columnas eliminando variables que producen data leakage variables basura y con alto porcentaje de NA. Se aplicó una estrategia diferenciada de encoding dividiendo las variables en ordinales nominales y de alta cardinalidad usando OrdinalEncoder OneHotEncoder y Frequency Encoding respectivamente llevando el dataset a 94 columnas finales.
El RandomForestClassifier con GridSearchCV obtuvo un ROC AUC de 0.6539 en test con un Recall de 59.28% y tras seleccionar las 25 variables más importantes mediante Feature Importance el Recall mejoró a 67.32% manteniendo el ROC AUC prácticamente igual en 0.6541. El análisis con LIME permitió identificar que variables como bc_util, fico_range_high y mo_sin_old_rev_tl_op fueron las más influyentes en las predicciones individuales del modelo.
En PySpark se replicó el mismo enfoque de modelado con RandomForestClassifier obteniendo un AUC de 0.7676 y completando el grid search en la mitad del tiempo que scikit-learn gracias al procesamiento distribuido. En general el modelo muestra un desempeño moderado con capacidad para detectar aproximadamente 7 de cada 10 defaults reales lo cual es un resultado aceptable considerando el desbalance de clases del dataset y la complejidad inherente de predecir incumplimientos financieros.